

Assignment #3
Assignment 3: Computational Lighting
Assignment Description
For this assignment, we are to use multiple images with variable light positions in order to create several lighting effects, as well as create a sort of cartoon image.
*All images are shown at a lower resolution. Please click on them in order to see them at full resolution. *
Images
DATASET
We were provided with the choice of two datasets. One was the numerous frames of this movie.
Each frame constitutes of an image where its light position varies.
The other dataset provided was the bronze dataset in which a bronze sculpture was photographed under different lighting, with each light changing positions. This dataset can be downloaded here . The bronze dataset was the one used for this assignment. Here are a select few images from the dataset




From this dataset we were to create three images. The first should have no (or few) shadows, which shall be called the shadow composite. The second image was to implement the synthetic lighting technique illustrated by Paul Haeberli while our third image was to create a “cartoon” image based upon the Non Photo Realistic (NPR) Camera’s Depth Edge Detection techniques created by Ramesh Raskar , et al.
The first image was originally designed to be created by taking the 3rd largest pixel from an array of N intensity images. Once we acquire which pixel of N we want, we then extract its RGB values and input them on the pixel
NOTE: The following images were created after the method was perfected. The functions were tested with the images I took. For further information concerning the development of all the functions, click here
Image #1: Shadowless Image
Max

Median

Ordered

Synthetic Lighting


Interesting Output: These images were taken by not using the ambient image. They’re of no significance to the assignment whatsoever

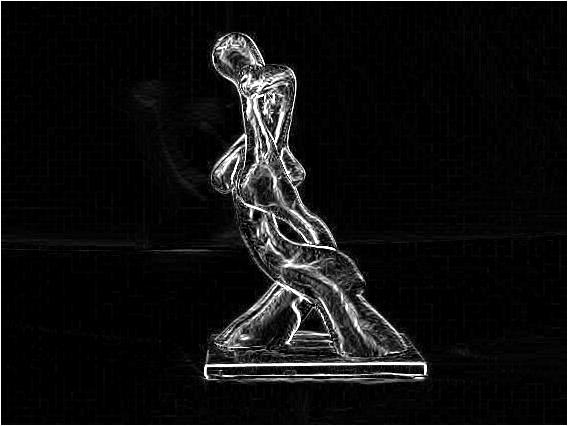
Cartoon Image
Images created under basic NPR algorithm:


Images produced with modified NPR method

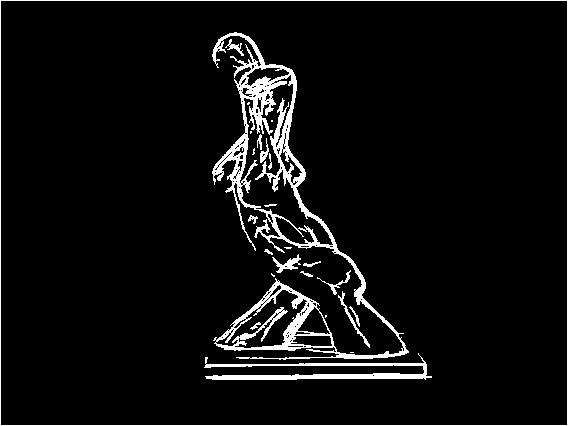

Images taken
New Dataset
Image#1: Shadowless Image
Max

Median

Ordered

Synthetic Color Image

Cartoon Image
Images created under basic NPR (using only 4 images):

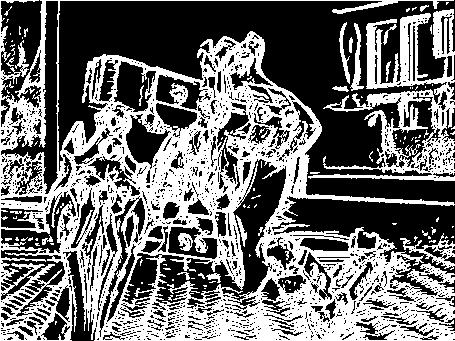

Images produced with modified NPR method


The images taken were at my apartment, using some LEGO’s ™ I bought for this assignment. They were posed in what I considered some interesting positions, so as to generate a lot of shadows. Here are some of the images from the dataset




The last two images have noticeable artifacts, in particular the last one where I inadvertedly appeared on camera. Rather than retaking the entire set of images again (which may have resulted in the same problem, as the cord for my lamp was limited and there’s not much space around the table for me to move further back), I decided to test to see if I could eliminate as many artifacts and shadows as I could.
Image #1: Shadow-less Image

Output #1: The previous image showed that the function was working. However, notice the artifacts (the lamp and my hand), on the topleft most on the screen. Also, each pixel’s intensity was the third highest in N images. I decided to remove the image that was saturating the most (ie. the one where my hand appeared), to see how it would change the image.

Output 2: The previous image shows the artifact removed. However, the image has too many shadows for it to be acceptable as a shadow-less image. As such, I decided to add the image again, only this time the function was changed to extract from the thirdmost highest pixel to the secondmost highest pixel.

Final Image : Though the previous image shows the artifact as clear as in the first image, it eliminates most of the shadows around all 3 figures. Note however that the shadow casted by the sword was not possible to remove with this method
Synthetic Color Image


Output#1: These two images were generated using the algorithm described previously (Click images to see them in greater detail). The colors were generated at random. Note that these images seemed very saturated with color, and that the artifacts still made a very large presence on the final image. As such, I decided to apply a dynamic weight to each of the N images as I added them. My first idea was to create an 1/max(median) weight, where the maximum value of the median values of one image would be inverted and used as a weight.


Output #2: These two images were created using a weight of (1/max(median)). Note that though the artifacts have largely disappeared, the image has become very dark. As such, it was necessary to create a threshold value by which, should we exceed it, the weight of 1/max(median) would be applied. The threshold chosen was if a pixel’s R, G, or B exceeded 55. 55 was chosen based on observation of the images as the threshold was changed to see how low the threshold could be set before the output became unacceptable.



Final Output: These last images were generated using the method described as a solution to Output #2. Note that the artifacts are largely removed from most of the images. Also, notice that though the background is not as detailed as it was in Output #1, the image is not saturated and the colors appear to be actually reflecting a colored light.
Cartoon Image
Using the exact technique described by Prof. Raskar, these are the output:

Output #1: The first image is the edges produced by taking four images where the light focus was to the left, right, top and bottom of the camera. The second image produced is the Canny style edges of the same image. Notice how detailed the canny-edge detection technique generated a more detailed, albeit more noisier image. The reason why was most likely due to the fact that the light sources of the images were not exactly to the left, right, top or bottom of the camera.
In order to take advantage of this technique, as well as implemented with multiple light sources that were not exactly perpendicular to the camera, instead of determining the x, y location of where the light source was, I decided to detemine the angle of where the light source was coming from, relative to the near center of the object photographed. I measured the angles through Photoshop’s measure tool. Some examples of measurements:

Angle measured as 120.3 degrees

Angle measured as 90 degrees
I then took these angles and combined both the horizontal and vertical sobel filters with sine and cosine, while subtracting the intersection of both. (To be exact: ” abs(cos((angle*pi)/180)).*d1h + abs(sin((angle*pi)/180)).*d1v – (abs(cos((angle*pi)/180)).*abs(sin((angle*pi)/180)).*(d1h.*d1v)), where d1h and d1v correspond to the horizontal and vertical sobel filter of an image.
 confidence10images.jpeg
confidence10images.jpeg
Output #2: Notice how the Edge picture (first one) is more detailed than the edge picture in output 2.

Final Output

Fun Picture: I decided to use the Edge picture not as for outlines for a cartoon, but rather as a mask over the shadowless image.
Links
.zip files that has all the Matlab Code, as well as the images taken